
Redis 怎么运作的
一、Redis 的底层结构
redisDB 结构
typedef struct redisDb {
dict *dict; /* 主键空间 */
dict *expires; /* 过期时间字典 */
dict *blocking_keys;
dict *ready_keys;
dict *watched_keys;
int id; /* DB编号 */
long long avg_ttl; /* 平均TTL */
unsigned long expires_cursor;
} redisDb;dict *dict
指向一个 dict 结构体实例,存储所有 key-value
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx;
int pauserehash;
} dict;其中 dictht 就是真正的哈希表
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;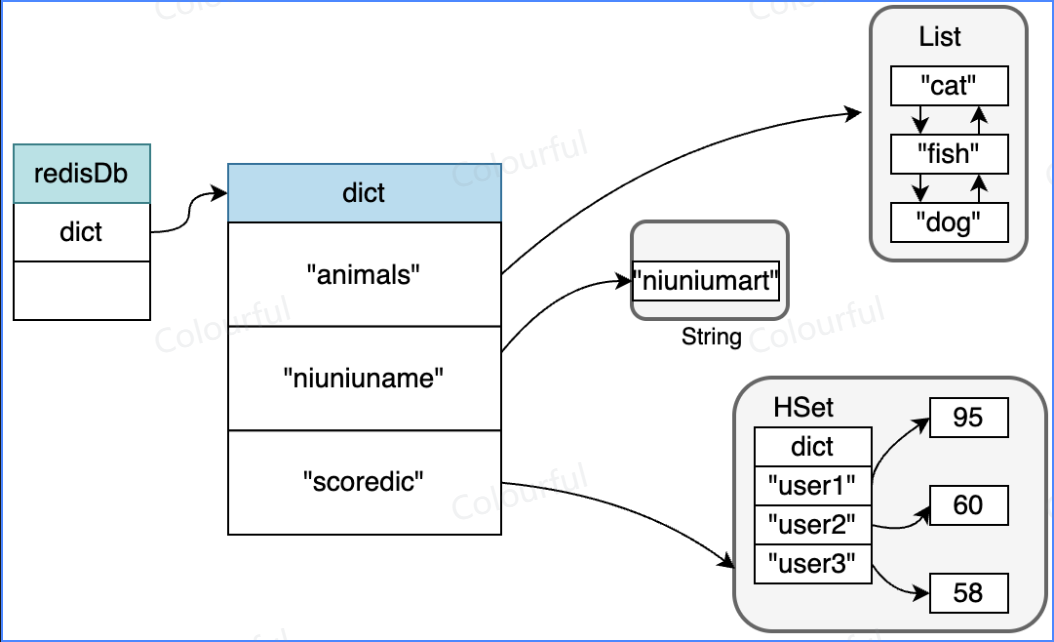
过期键 dict *expires
过期键存在 expires字典上
Redis 数据可以设置 过期时间,时间到后这些对象便可自动回收
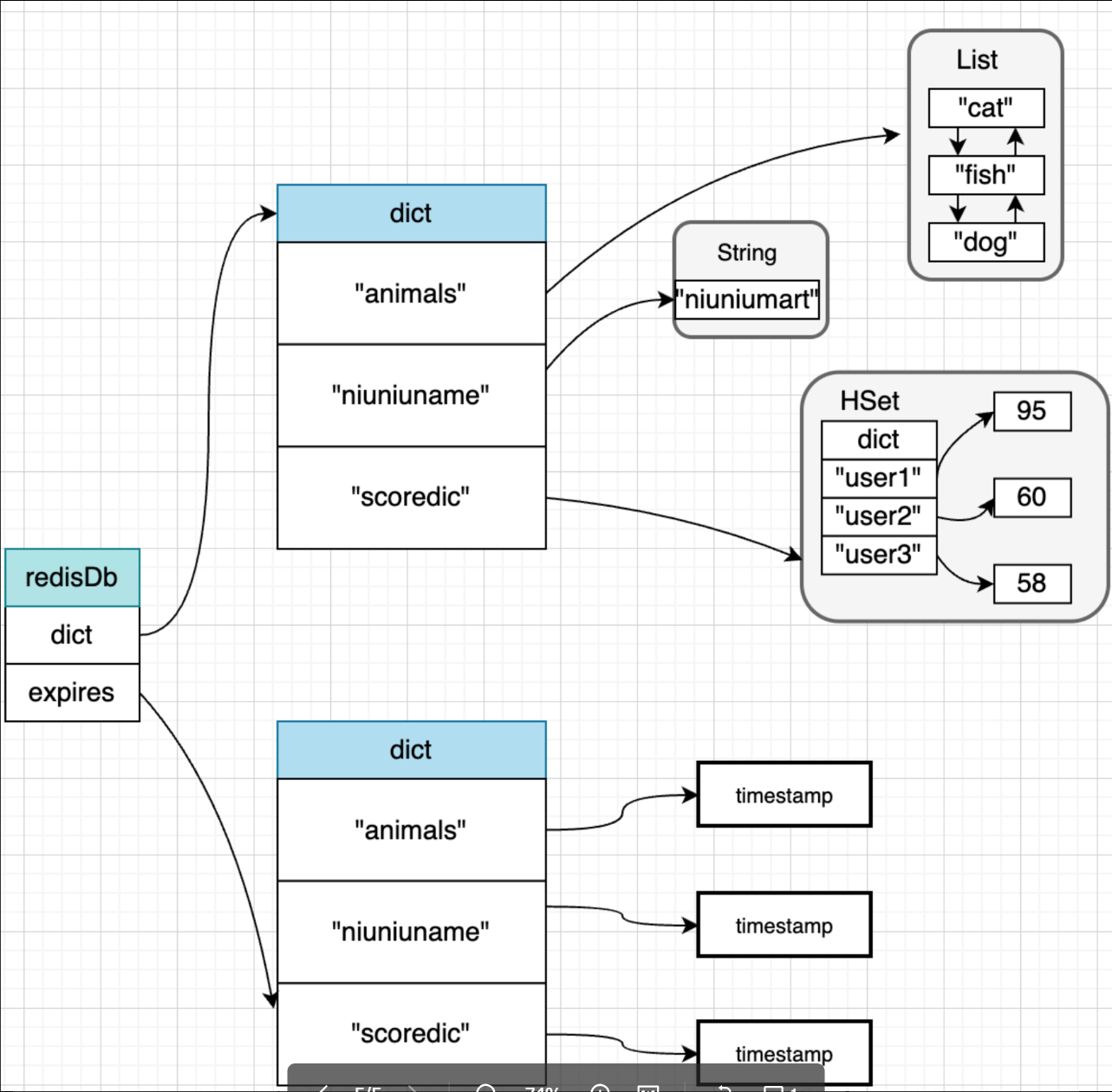
这里的 dict 和 expires 中的 Key 对象,实际都是存储的 String 对象指针:dict 和 expires 中的 Key 实际存储的都是 指向内存相应字符串的地址
二、Redis 是单线程还是多线程
核心处理逻辑,单线程:
接收客户端请求 → 解析请求 → 进行数据读写等操作 → 发送数据给客户端
辅助模块,多线程,如:复制模块,异步流程(UNLINK、FLUSHALL ASYNC 等非阻塞的删除操作),网络 I/O 解包从6.0开始用的是多线程
Redis IO 多路复用
阻塞 IO:
处理连接A → 等A数据(卡住)→ 才能处理B
IO 多路复用:
监听所有连接 谁有数据 → 处理谁 没有数据 → 不阻塞
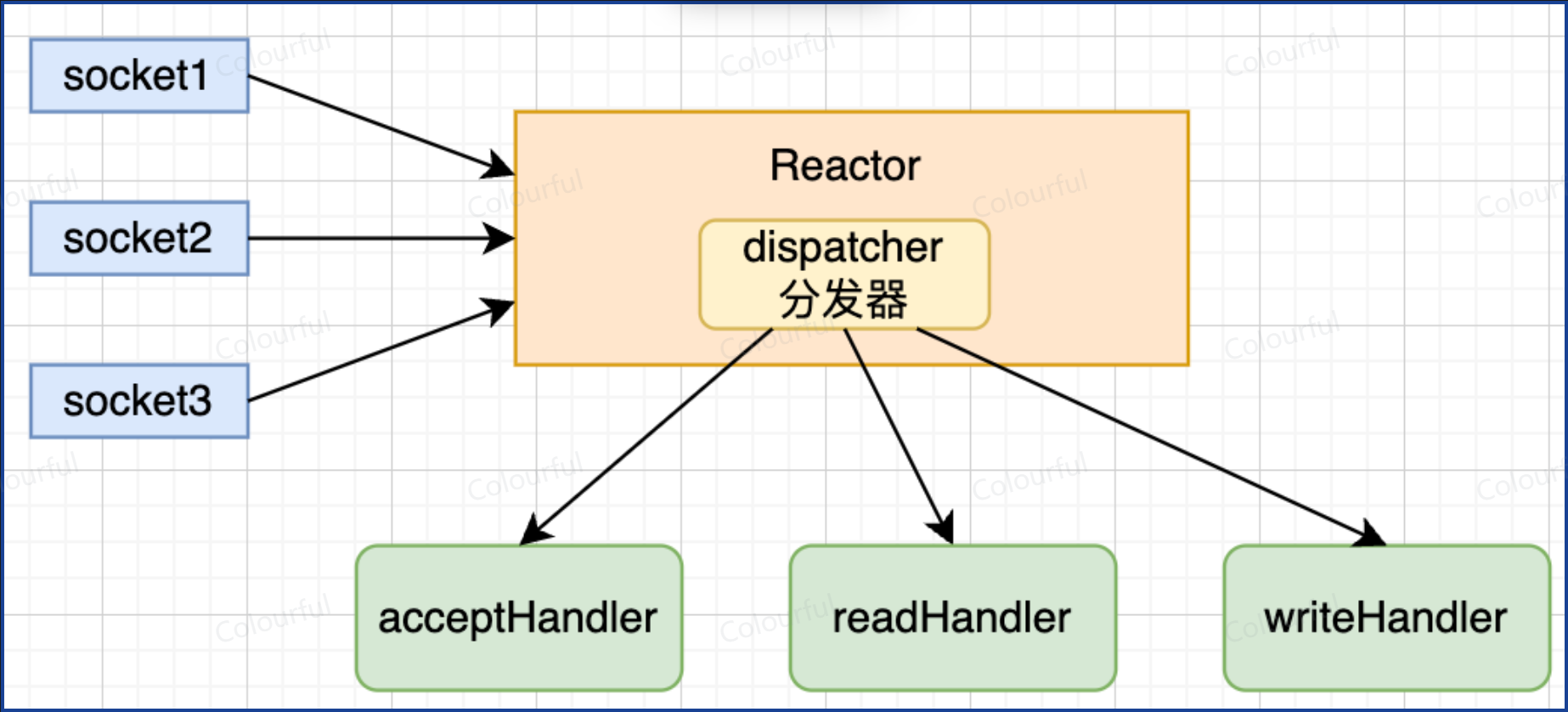
IO 多路复用本质是: 让一个线程管理多个 socket,避免在单个 socket 上阻塞
当 Redis 正在处理一个请求时,新请求会先存放在操作系统的 socket 接收缓冲区中,等 Redis 处理完当前事件,再通过 epoll 机制获取并处理新请求
针对 I/O 多路复用,Redis 做了一层包装,Reactor 模型
三、Redis 为什么选择单线程做核心处理
Redis大部分操作都是在内存上完成,内存操作本身非常快,多线程带来的 锁竞争 和 线程切换开销 反而会降低性能
同时单线程可以避免并发问题,保证数据操作的原子性,使系统实现更简单、更稳定
Redis 的瓶颈通常在网络 IO 而不是 CPU,所以单线程足够支撑高 QPS(10w/s 的QPS)
四、单线程为什么能这么快
基于内存操作:内存的读写速度比磁盘快几个数量级
高效的数据结构:比如ziplist,hash,跳表,一种对象底层有多种实现来应对不同的场景
单线程:节省上下文切换带来的开销,不存在资源竞争,避免了死锁的发生
I/O 多路复用:可以在只有一个线程的情况下,同时监听成千上万个客户端连接,解决传统 IO 模型中每个连接都需要一个独立线程带来的性能开销。
五、Redis 6.0 使用多线程
原因:Redis 6.0 之后,采用多个 I/O 线程来处理网络请求,这是因为随着网络硬件的性能提升,Redis的性能瓶颈有时就会出现在 网络 I/O 的处理上(巨大的单线程在进行同步读写 I/O 的时间,单核 CPU 有时候也不够用了),对解包和发包这两个操作进行了多线程优化
6.0多线程默认是关闭的,兼容以前的(大多数用户认知Redis是单线程),多线程并不是必要的,在大多数场景不开启也够用。
开启多线程处理客户端请求,需要把 Redis.conf 配置文件中的 io-threads-do-reads 配置项设为 yes
Redis 6.0 的多线程主要负责网络 I/O 的读写:从 socket 中读请求,以及向 socket 返回结果(写)用到了多线程
Socket 是操作系统提供的 网络通信接口,本质是 文件描述符。客户端和服务端通过 Socket 建立连接后,服务端从 Socket 读取客户端请求数据,执行完成后再将结果写回 Socket 返回给客户端