String
字符串,最大为512MB
增 / 改:SET key value (覆盖写), SETNX key value (不存在才执行)
删: DEL key。
查:GET key, MGET key1 key2 (批量获取)
底层编码:
INT:存一个 long 整型
EMBSTR:字符串小于等于阈值字节,使用 EMBSTR 编码
RAW:字符串大于阈值字节,使用 RAW
List
一组连接起来的字符串集合
增: LPUSH key value (左插), RPUSH key value (右插)。
删: LPOP key, RPOP key (左右弹出),LREM key count value(移除值等于value的元素。count=0,移除全部;count>0,从左到右移除count个;count<0则从右到左移除count个),DEL key(删除整个list)
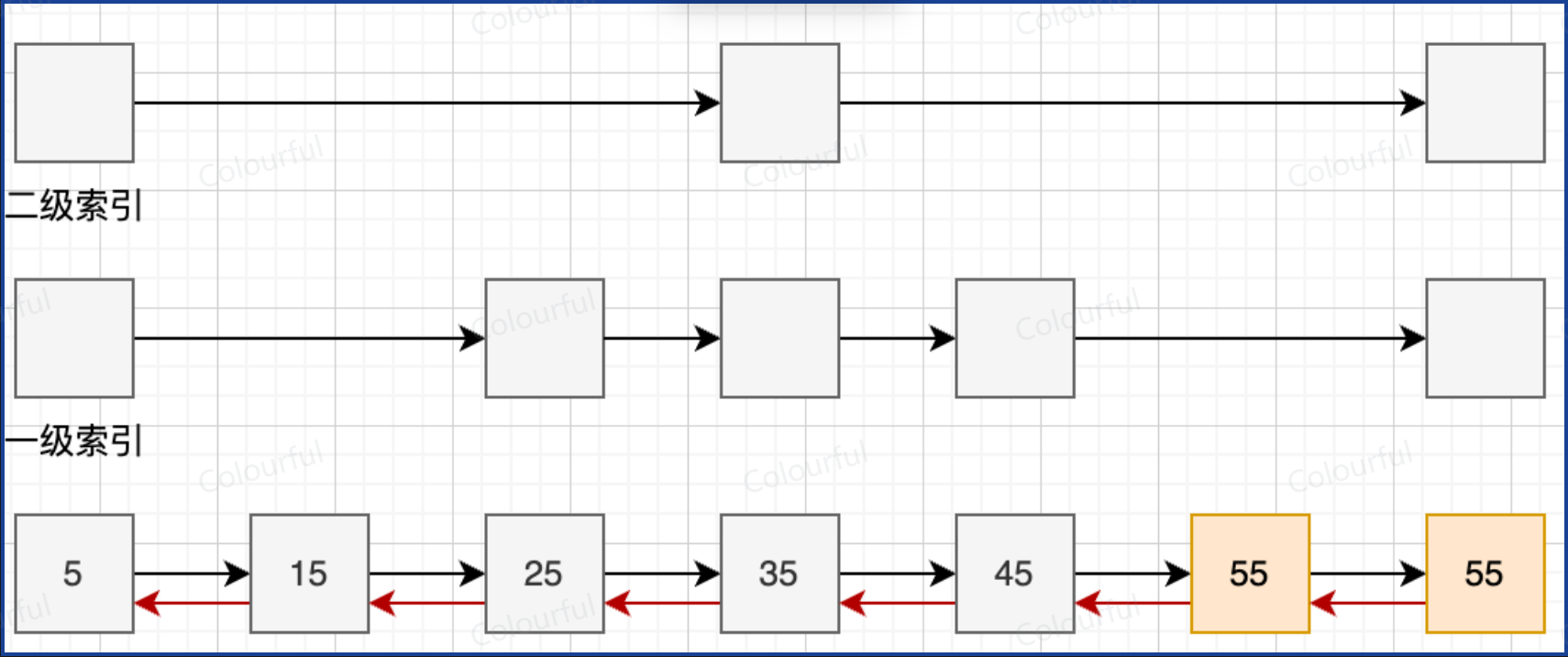
查: LRANGE key start stop (查start到stop角标的元素,如 0 -1 查所有),LLEN key(查看List的长度,即List中元素的总数)
底层编码:
ZIPLIST:
列表对象保存的所有字符串对象长度都小于64字节
列表对象元素个数少于512个(LIST的限制)
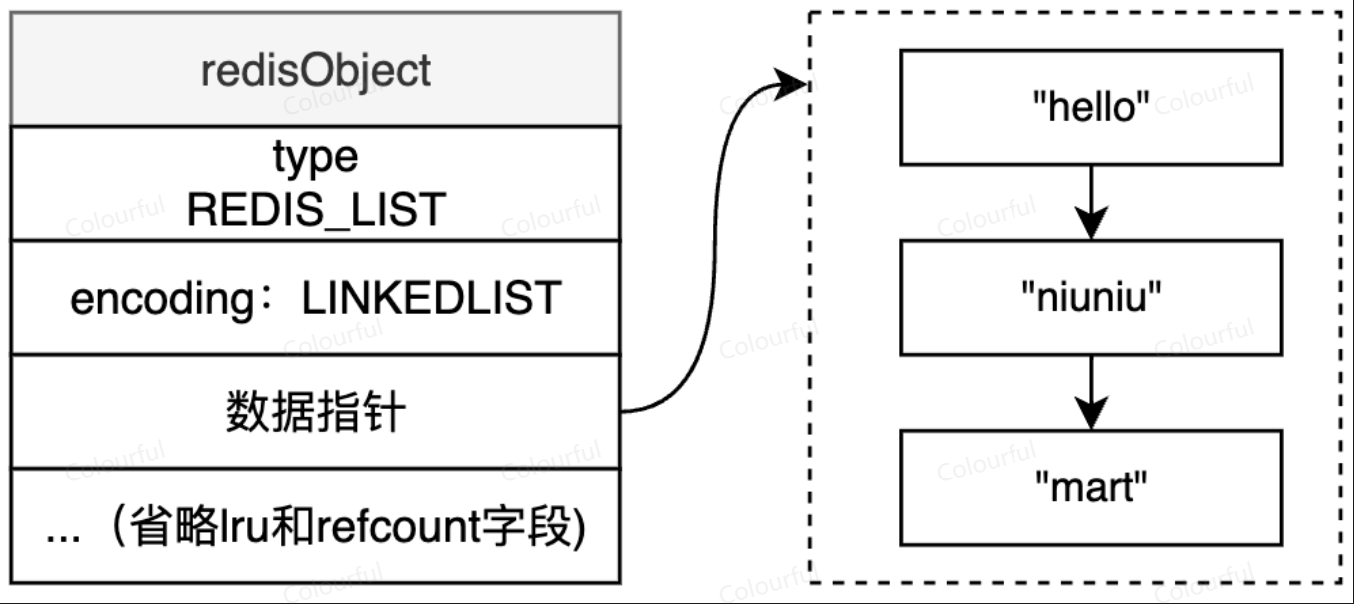
LINKEDLIST
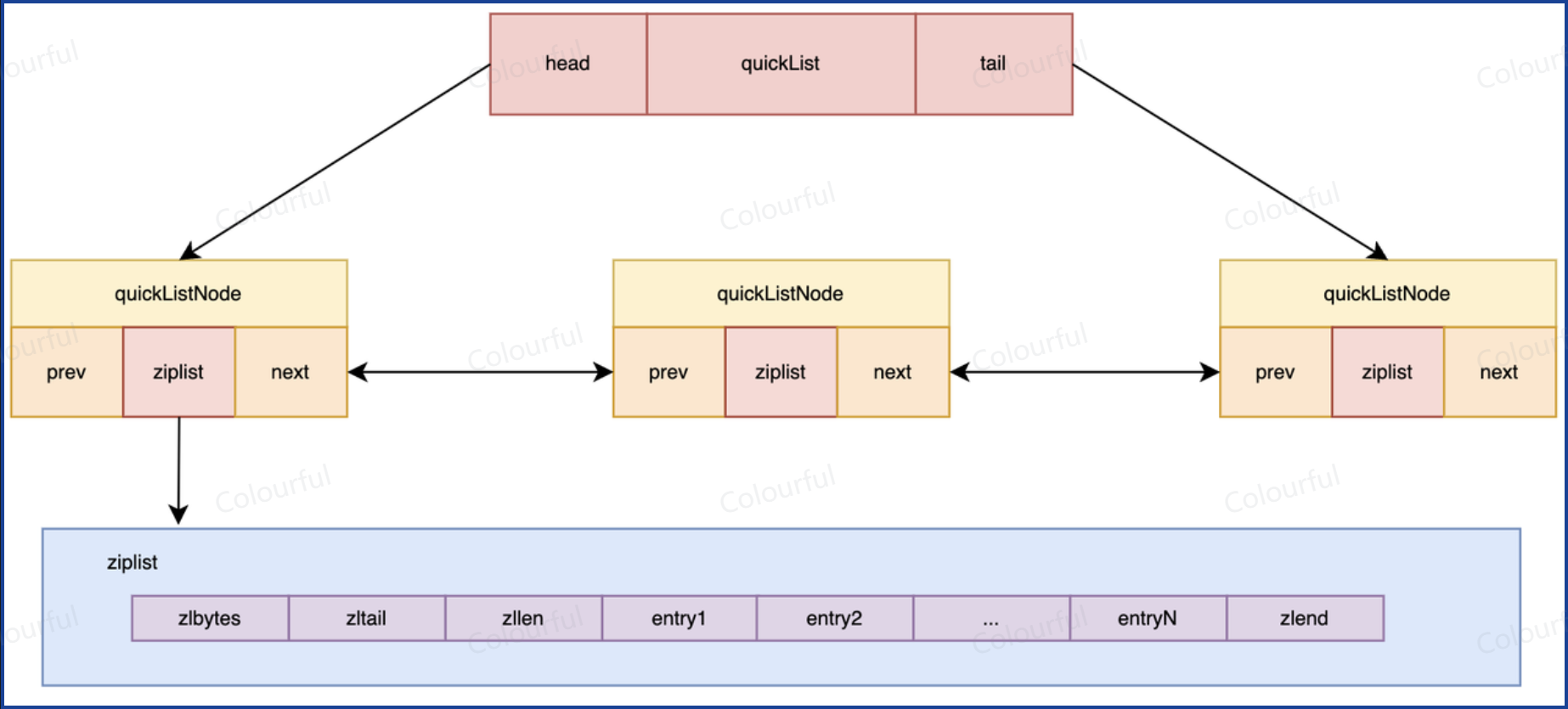
QUICKLIST:ZIPLIST 和 LINKEDLIST 的结合体。LINKEDLIST 原本是单个节点,只能存一个数据,现在单个节点存的是一个 ZIPLIST(链表形式串起来的 ziplist)
LISTPACK:压缩列表:QUICKLIST 里的 ZIPLIST 被 LISTPACK 取代了(连锁更新问题)
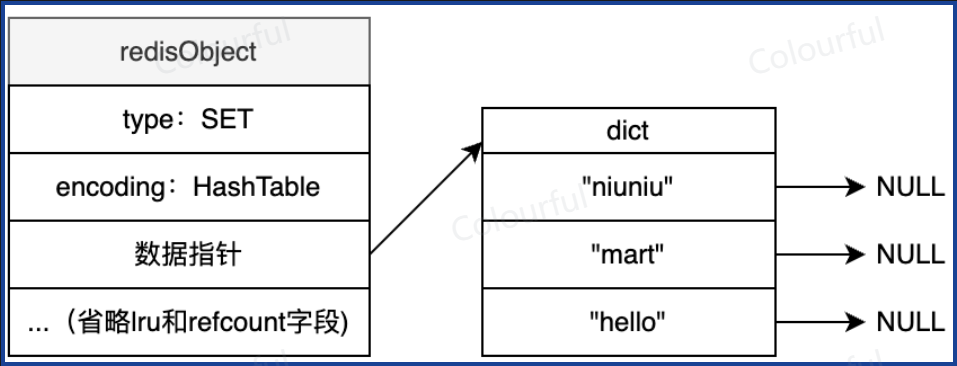
Set
不重复无序的字符串集合
增: SADD key member1 [member2]
删: SREM key member 删除值为member的元素
查:
SMEMBERS key(查看集合的所有元素)SISMEMBER key member(查看是否存在,O(1) 高效)SCARD key(查询集合元素个数)
集合运算:
SINTER k1 k2(交集),SUNION(并集),SDIFF(差集)
底层编码:
INTSET:集合元素都是整数,元素数量不超过512个。查询时二分查找
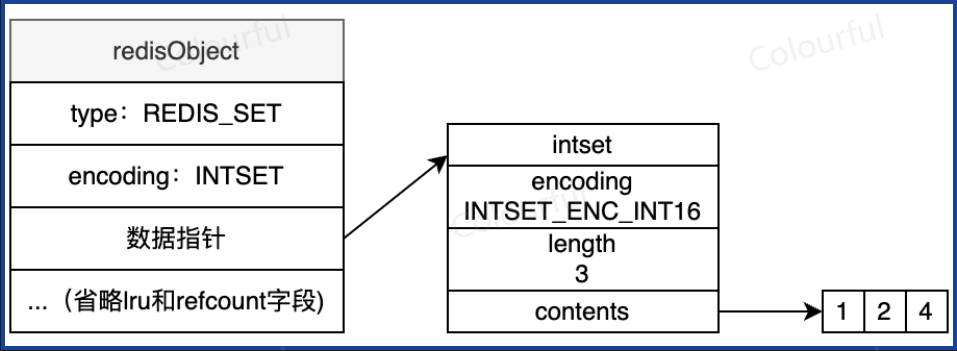
HASHTABLE:O(1) 时间就能找到一个元素是否存在
Hash
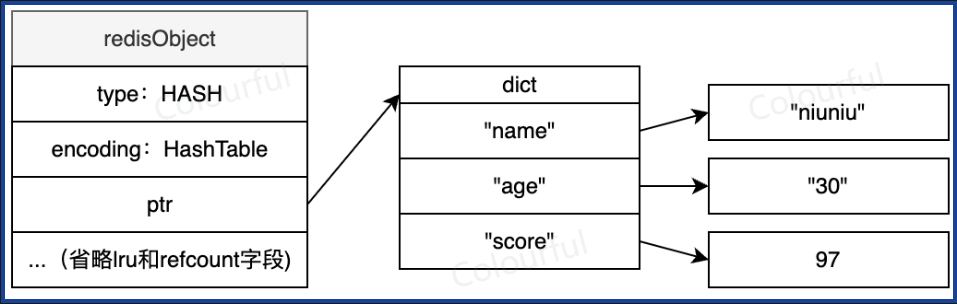
field、value 都为 string 的 hash 表
增 / 改: HSET key field value, HMSET,HSETNX
删: HDEL key field1 [field2],DEL key
查:
HGET key field(查单个)HGETALL key(查所有,慎用:O(N),容易阻塞)HEXISTS key field(判断字段是否存在)HLEN key(查找Hash中元素总数)
底层编码:
ZIPLIST:Hash 对象保存的所有值和键的长度都小于64字节,Hash 对象元素个数少于512个
HASHTABLE:Set 中的 value 始终为 NULL,在 Hash 中,是有对应值的
ZSet
有序集合,分值相同按字典序排序
增 / 改: ZADD key score member[score member] (Score 可为浮点数)
删: ZREM key member
查 (排名):
ZRANGE key start stop [WITHSCORES](从小到大)ZREVRANGE key start stop(从大到小,排行榜常用)ZSCORE key member(获取分值)
底层编码:
ZIPLIST:列表对象保存的所有字符串对象长度都小于 64 字节,列表对象元素个数少于 128 个
SKIPLIST + HASHTABLE:SKIPLIST 快速定位到数据所在,HASHTABLE 配合查询在O(1) 时间复杂度查到成员的分数值
Redis 对跳表实现:多加了一个回退指针