
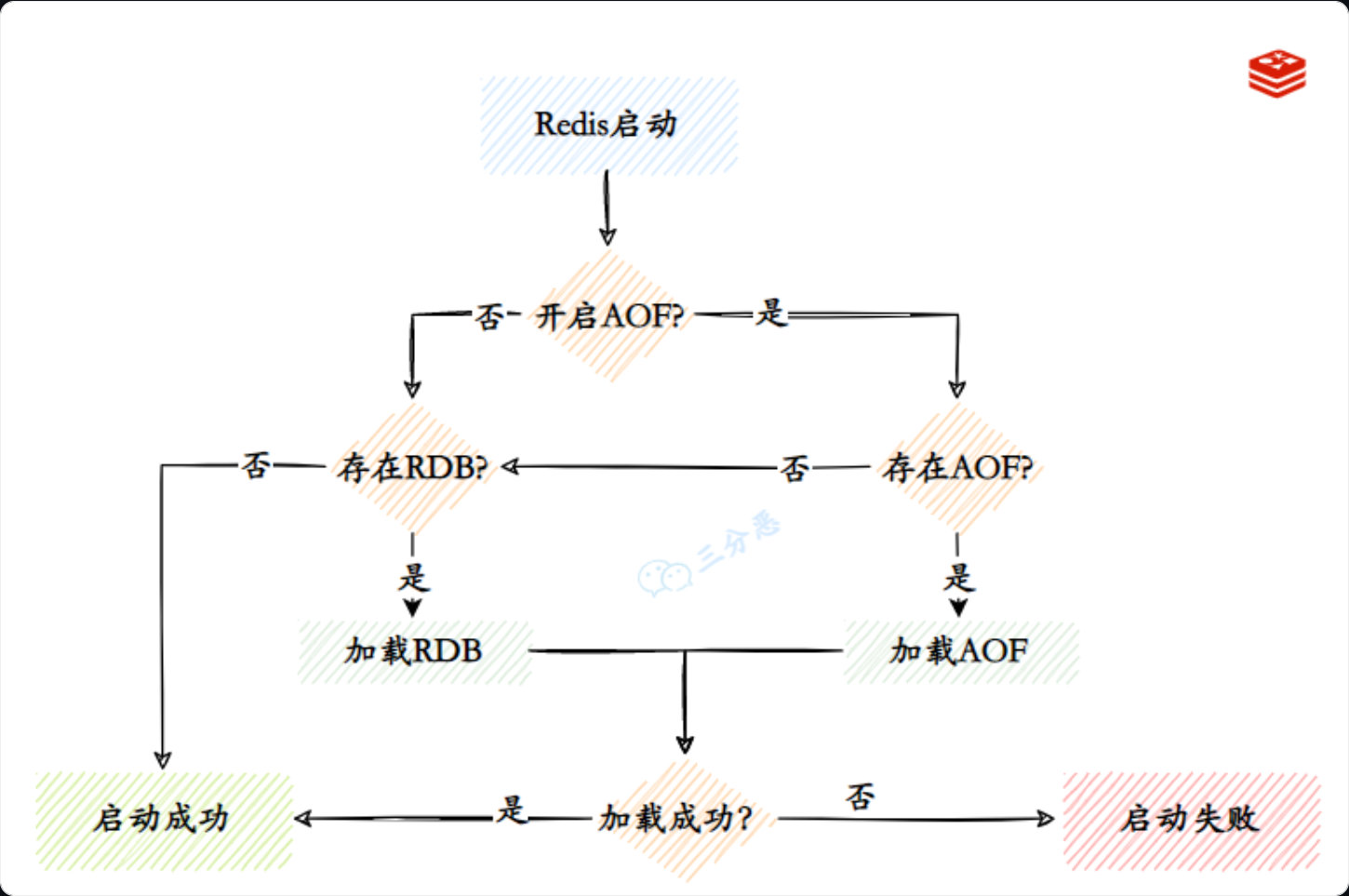
RDB 和 AOF
持久化
当程序重启或者服务崩溃,数据就会丢失,那么业务如果希望重启后数据还在,就需要持久化,即把数据保存到可永久保存的存储设备中
RDB
基本概述
RDB 本质就是二进制形式的快照文件
RDB 是 Redis 的一种持久化机制,通过生成某一时刻内存数据的快照并保存为二进制文件,在 Redis 重启时加载该文件来恢复数据。
触发时机
手动触发
BGSAVE:最常用,后台子进程生成,不阻塞主线程SAVE:阻塞主线程(线上基本不用)自动触发:配置了 save interval num,每隔interval秒,至少有num条写数据操作(增删改),就会激活RDB持久化
Redis 正常关闭触发
主从复制触发:在主从复制的全量同步阶段,主节点会生成 RDB 文件并发送给从节点,用于初始化从节点数据。
执行过程
RDB 生成时,Redis 会 fork 子进程
子进程将内存数据写入一个临时 RDB 文件
写入完成后将这份文件替换掉旧的 RDB文件
dump.rdb就是Redis RDB生成的二进制快照文件
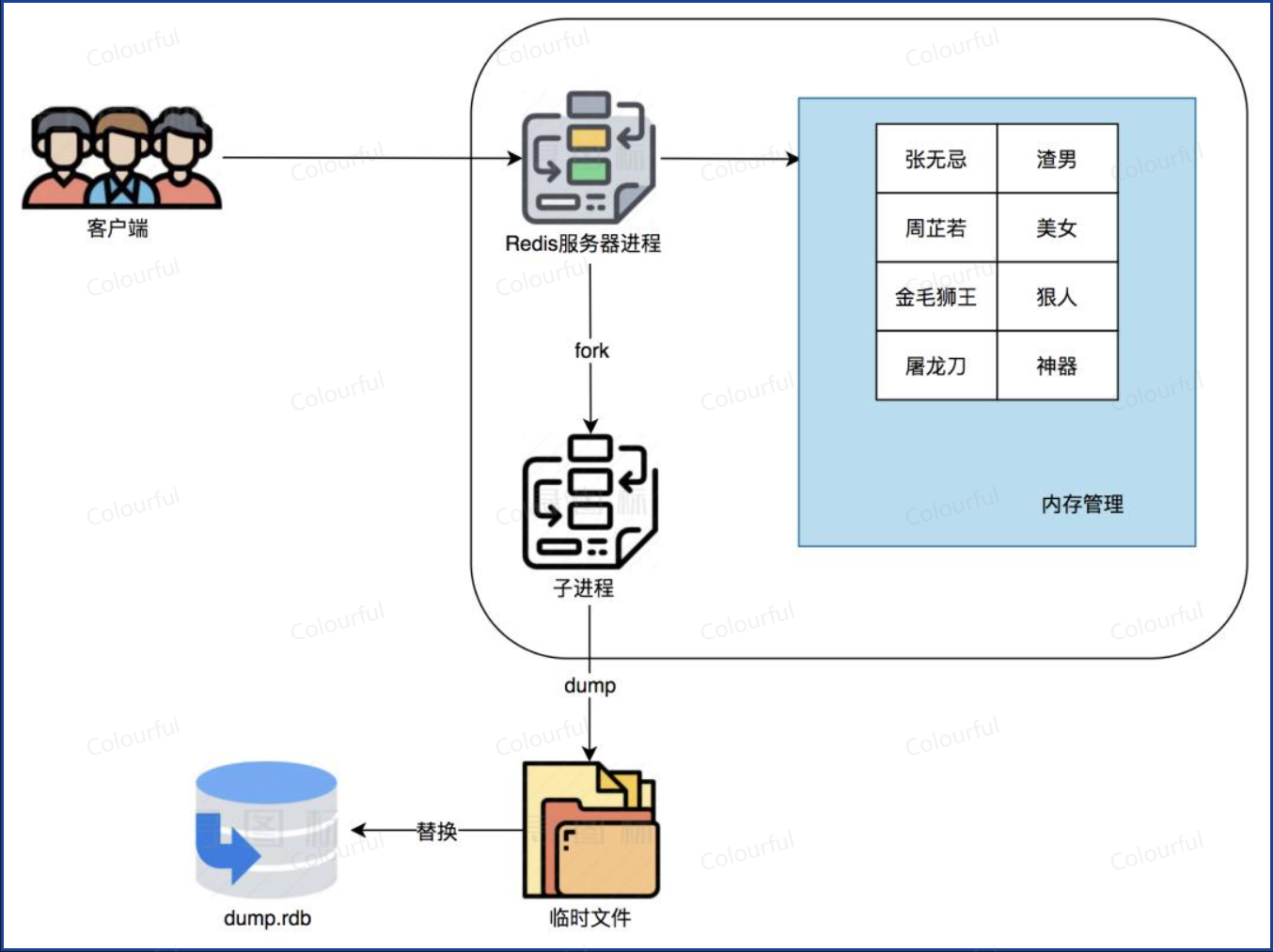
在 RDB 持久化过程中,Redis 还可以执行新的命令,数据是可以被修改的,这就要用到写时复制机制
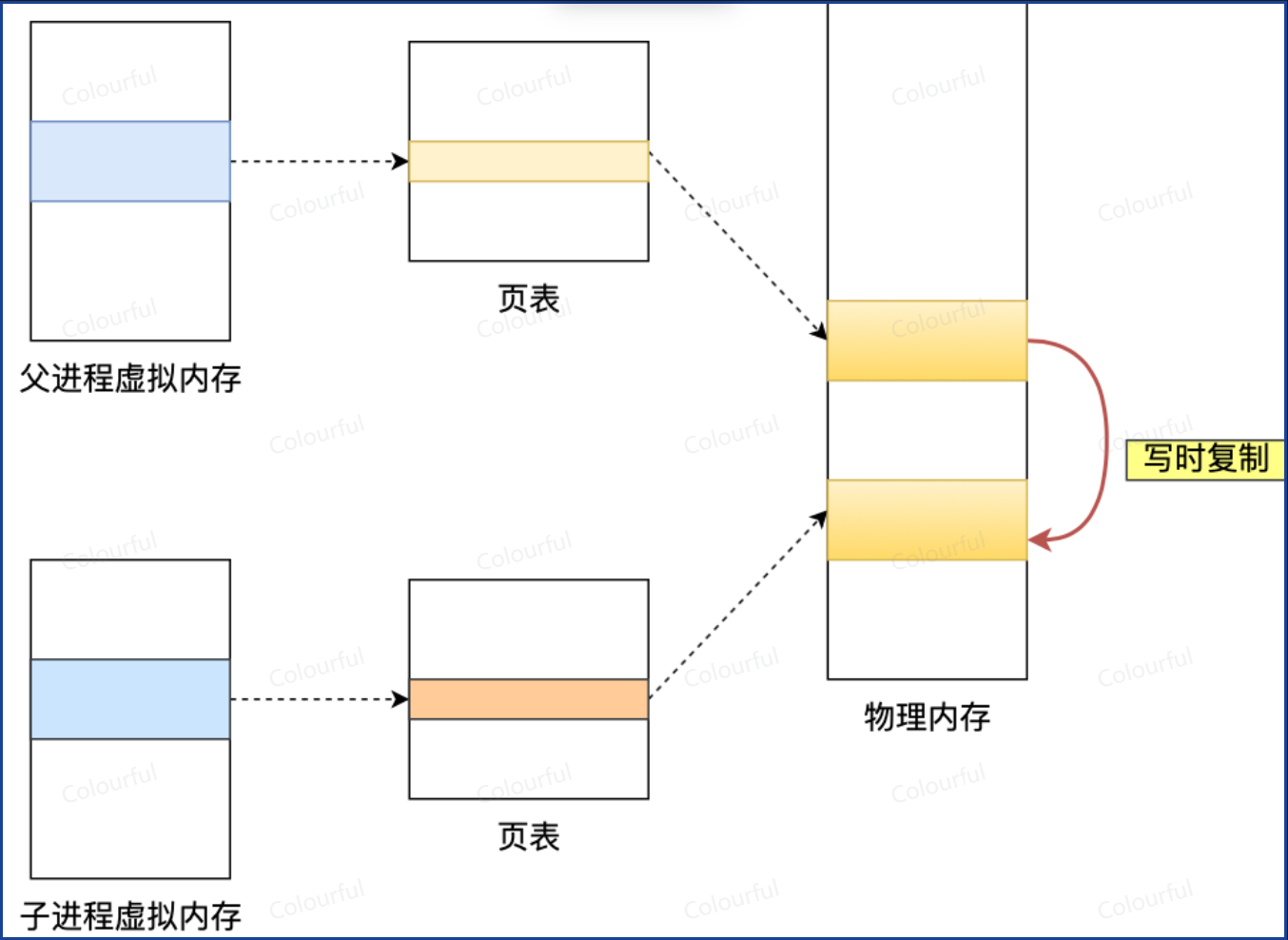
写时复制
RDB 的写时复制中,当主进程发生写操作时,会复制出新的内存页供主进程修改,子进程仍然基于 fork 时刻的旧内存生成 RDB,从而保证快照一致性(必须对应一个明确的历史时刻,保证“某一确定时刻”的数据完整性)
AOF
基本概述
AOF 是 Redis 提供的一种持久化方式,Redis 在执行写命令后,会将该命令追加写入 AOF 文件中。Redis 重启时通过重新执行 AOF 中的写命令来恢复数据。AOF 支持不同的刷盘策略,在数据安全性和性能之间进行权衡。
AOF 写入流程
命令执行完成后先追加到用户态的 aof_buf 缓冲区
然后通过 write 系统调用写入到操作系统内核缓冲区
是否以及何时调用 fsync 将数据真正刷入磁盘,由 appendfsync 策略控制,默认 everysec 由后台线程每秒刷盘一次。
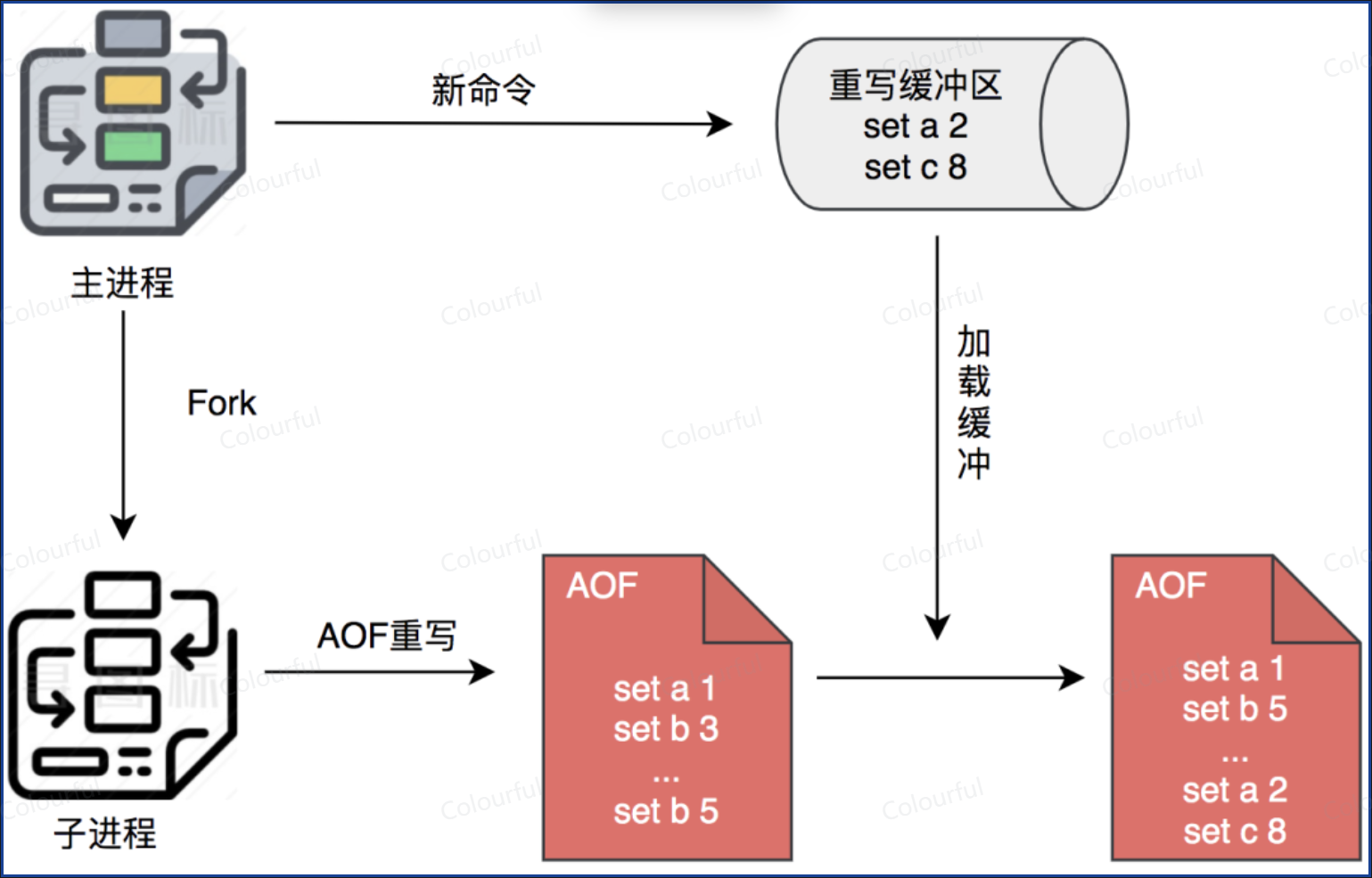
AOF 重写
AOF 文件是不断重写的,为解决出现文件膨胀问题,Redis采用重写的方式:
本质就是:根据Redis当前内存的数据状态,生成一份最精简的 AOF 文件
重写过程中如果有新的数据写进来,Redis会将新写进来的数据记录在原有的 AOF缓冲区(保障随时宕机可恢复),以及 AOF重写缓冲区(重写完成后数据完整)。一旦新AOF文件写入完毕,Redis主进程就会将 AOF 重写缓冲区内容,追加到新的 AOF文件,再用新 AOF文件替换旧AOF文件
附:AOF 缓冲区是为正常持久化服务的,数据会被频繁写出和清空,无法作为重写期间增量命令的可靠边界,因此 Redis 需要一个独立的 AOF 重写缓冲区,专门记录从 fork 开始到重写结束的所有写操作。
触发时机:
根据配置,默认超过64MB的情况下,相比上次重写时的数据大一倍
执行 bgrewriteaof 命令
对比
RDB 和 AOF 各自的优缺点?
RDB 是快照持久化,优点是文件小、恢复快、备份效率高
缺点是可能丢失两次快照期间的所有数据变更;
AOF 是命令追加方式,优点是支持实时持久化、数据丢失风险可以控制在 1 秒内甚至完全避免
缺点是文件大、恢复慢、性能开销更高
实际生产中通常结合使用两者,在安全性和性能之间取得平衡
什么时候用 RDB 什么时候用 AOF?
RDB 适合对数据实时性要求不高、追求性能和快速恢复的场景
比如:如果是缓存场景,可以接受一定程度的数据丢失,我会倾向于选择 RDB 或者完全不使用持久化以获得更高的性能
AOF 适合对数据安全性要求较高、希望减少数据丢失的场景
比如:像订单、支付这类核心业务,数据丢失将造成严重后果,那么 AOF 就成为必然选择
在实际的项目当中,我更偏向于使用 RDB + AOF 的混合模式。
混合持久化
混合部署实际发生在AOF重写阶段(不是同时开启RDB和AOF),将当前状态保存为RDB二进制内容,写入新的AOF文件,再将重写缓冲区的内容追加到新的AOF文件,最后替代旧AOF文件
此时AOF文件是:二进制数据+日志数据的混合体,所以叫混合持久化
可以大大降低AOF重写的性能损耗,以及降低AOF文件的存储空间,付出的代价则是降低AOF文件的读写行,但是实际开发,很少有人去读AOF数据的情况